Rise of the tidyverse
March 2021
Almost 40% of the R programming language is now built on the tidyverse.
The other day a friend said they would start teaching econometrics with R, and they wondered if they should teach it with the tidyverse, a suite of packages for data analysis.
Packages are how programming languages evolve. You take any language, and its users will change it over time to suit their needs.1 Developers change a programming language by writing plug-ins (“libraries” or “packages” of code) for others to freely download and use. There is a whole market for these packages, and it grows everyday.
Teaching R makes sense because most students go into industry, where nobody cares about Stata, and Excel is too limited. Plus there are now plenty of free econometrics textbooks written with R. But what about the tidyverse, or other packages for that matter?
There are tradeoffs to adopting a “dialect” of a language, because language adoption in general is a coordination game. It makes no sense to learn a new dialect if it will probably fizzle out, because who will you “speak” to? On the flip side, if a package takes off, and everybody starts speaking it, not learning it (and not teaching it) is a bad investment.
There is no crystal ball in this game, but you can get a sense of how a language is evolving by studying the package market. Recently I noticed that lots of new packages in R had the word “tidy” or something like that in the title (e.g., “tidyBayes” or “tidyQuant”). Packages like these are no doubt influenced by the “tidyverse”. But is R in general becoming “tidy”? I’m pretty sure the answer is yes.
Browsing the app store
CRAN is the marketplace or “app store” for R packages. For example, the package cdcfluview came out the other today (I picked it at random), and it has some tidyverse imports:
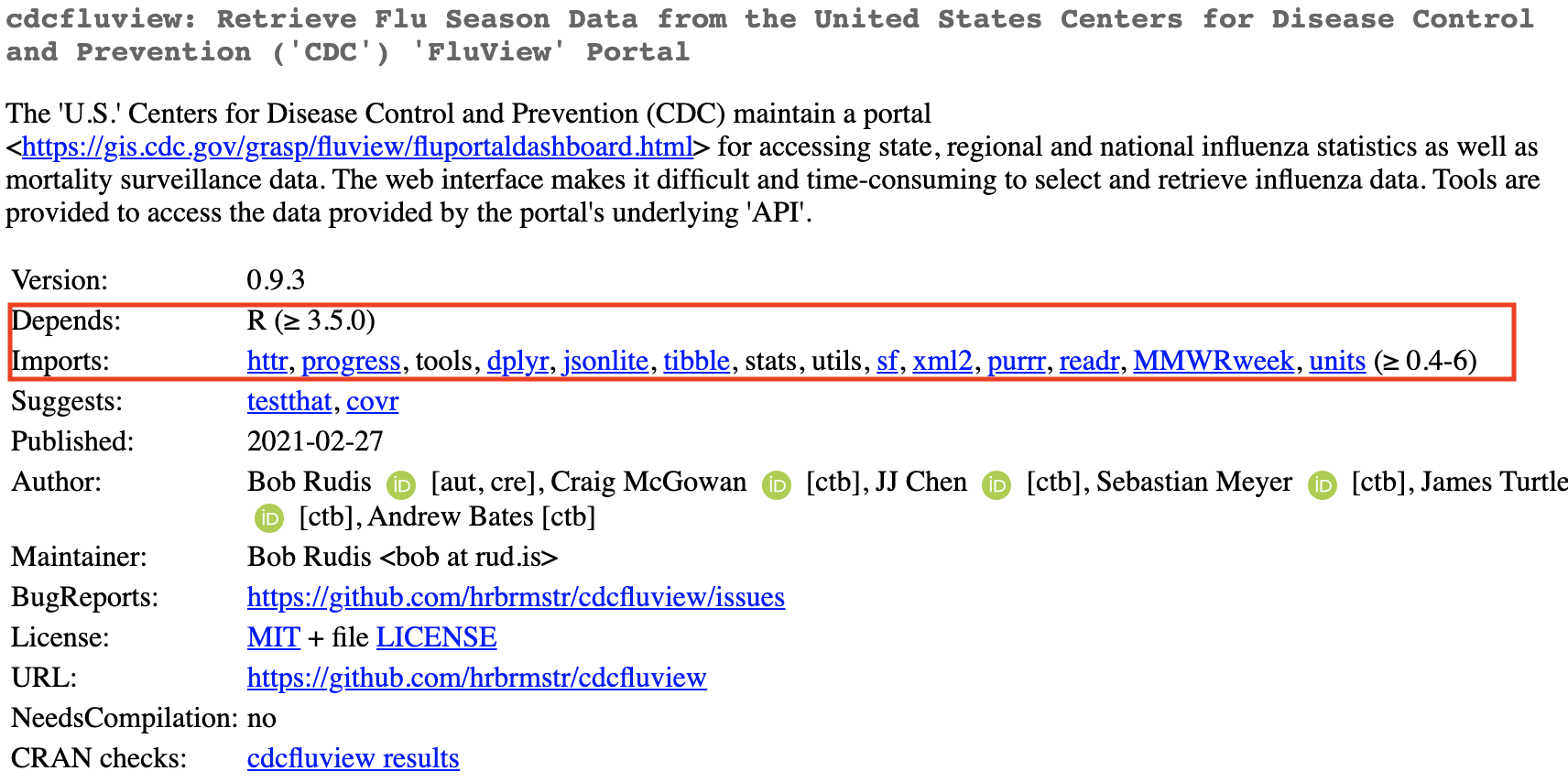
So I looked inside each active CRAN package and counted how many tidyverse packages it either “Requires” or “Imports” (i.e., the package is dependent on those packages to work).
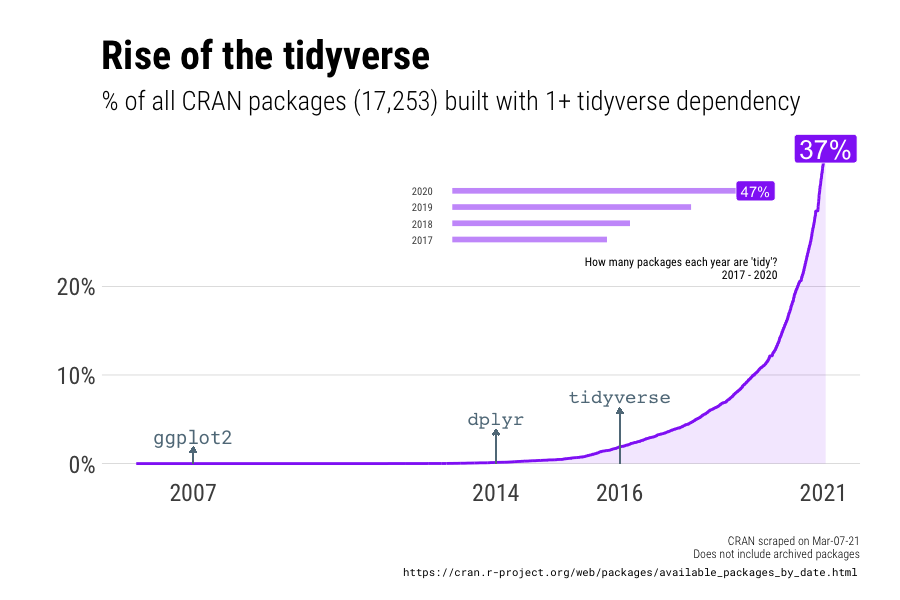
As of writing there are more than 17,000 active packages on CRAN since 2006. Almost 40% are built with a tidyverse dependency (and almost 50% if we start counting in 2017):
Last year there were 6,127 total new packages, half of them tidyverse-dependent. Two months into 2021 there are already 1,417 tidyverse-packages. If this exponential growth continues, there will be more than a million of these packages within the decade (that won’t happen, but still):
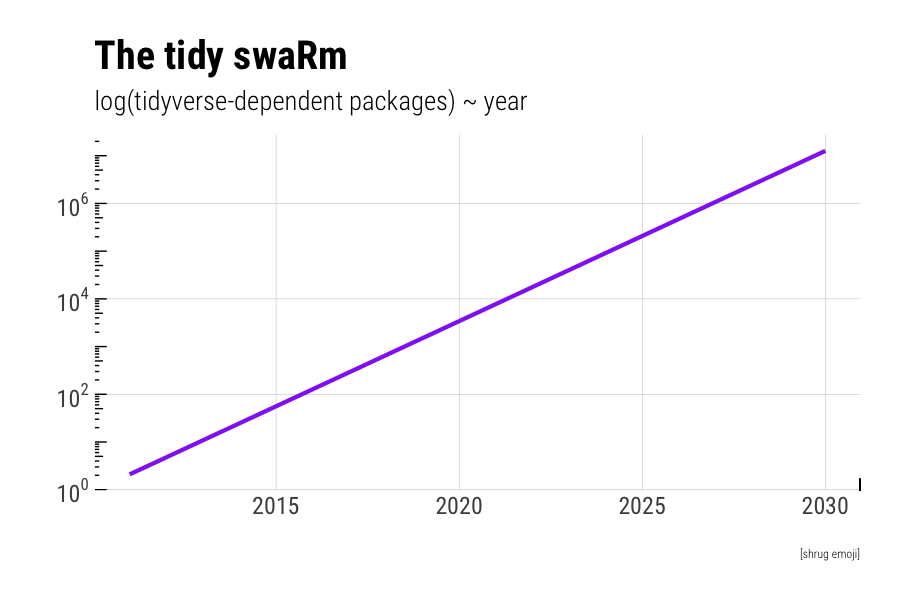
In general you want a language with big network effects. It’s pretty clear from these graphs that the tidyverse network effects are big, and getting bigger.
Why do you care about network effects? Because big networks means more users, and more users means faster problem solving. Coding is really about Googling an error message and hoping somebody on Stack Overflow – one of the most valuable public goods on the internet – already found a solution.
Of all the questions on Stack Overflow tagged “[R]” (about 390,000), more than 50% are related to ggplot2 or dplyr, two of the main tidyverse packages. If all of the 17,000 R packages were equally cited, each one would only comprise about 4% of all questions.2
Why is the tidyverse popular?
There are probably lots of reasons, but I will focus on two.
For one, tidyverse operations reduce the marginal cost of development time. The “tidyverse way” is just easier than the competition. Case in point, the webscraper I made for this post uses tidyverse stuff that reduces the task of extracting and cleaning data from web pages to just a few lines of code (scroll down for the GitHub link).
Second, and to me the more interesting reason, is that the strategic bundling of the tidyverse with other R products has made its propagation practically inevitable.
Ease of use
I’ll leave it for others to showcase the finer details (but here is a nice comparison of data manipulations with and without the tidyverse). Here are a couple ways I found teaching way easier with the tidyverse than “base R” (i.e., R with no extra packages).
First, the “pipe” operator (%>%), makes code easier to read and thus easier to write.
Instead of a “Russian doll” sequence of transformations like
1
mean(exp(sqrt(1:10)))
you have
1
2
3
4
1:10 %>%
sqrt() %>%
exp() %>%
mean()
which is more like natural language (“do this, then do that, then do this other thing”, etc.).
The pipe is a neat innovation that has spread to other languages) and is now on the verge of adoption by base R.
That is as close as it gets to “rewriting the dictionary” of a programming language.
(Although it will apparently be |> instead of %>%. It’s like British English versus American English!)
Second, the tidyverse “verbs” (functions) are intuitive, and as an added bonus, they help you avoid loops when doing basic stuff, like calculating a statistic by a grouping variable.
For instance, the price of a diamond varies with it’s cut. To see this, you could calculate the average and standard deviation price by cut with
1
2
3
4
5
for(i in unique(diamonds$cut)){
message("cut == ", i)
print(mean(diamonds[diamonds$cut == i,]$price))
print(sd(diamonds[diamonds$cut == i,]$price))
}
or you can just do
1
2
3
diamonds %>%
group_by(cut) %>%
summarise(mean(price), sd(price))
and move on with your life (or lecture, or even both).
Bundled up
Not everyone is convinced about the tidyverse.3 But I think they will soon be the minority.
That’s because the bundling of the tidyverse with core R products probably accelerated its adoption. It’s like the Apple ecosystem. You start with an iPhone, and then before you know it, you have a MacBook pro with a dozen adapters. Once you’re in, why leave?
You can see this bundling in a few places.
For starters, the packages are embedded into RStudio. RStudio is the main app for using the R language. RStudio is also a company (whose Chief Scientist is Hadley Wickham, creator of the tidyverse) that sells a bunch of products related to R language (which is free). They have not yet pulled a Windows anti-trust move by auto-installing tidyverse packages with the RStudio app. But it does come with a nice set of tidyverse cheat sheets, and the company has made a lot of efforts to capture the higher education market.
RStudio also heavily promotes the tidyverse on their website, and naturally, how to build packages for the tidyverse using so-called “tidyverse design” (e.g., “data masking” – the first argument to a function should be a dataframe).4
It also helps that the packages themselves are bundled.
In the plot of packages over time you can see the growth kick-in around 2016, when library(tidyverse) was introduced.5
All that snippet does is load a bunch of other packages.
But it’s convenient to not have the first fifty or whatever lines of a file filled up with package calls.
It’s also convenient for teaching: just have students on day one run install.packages("tidyverse") and they’re good to go.
Turns out these kinds of strategies are pretty common in programming languages. For instance, MATLAB offers heavy price discounts at many universities. Students “get hooked”, employers pay the sticker price for licenses so they hire top talent, and since the costs of learning a new language are high, the cycle continues. The R language is free, and so are all its packages, so the tidyverse can’t price discriminate like MATLAB. Bundling is the obvious alternative.
The last frontier
What else will the tidyverse conquer?
To me, the most interesting development is tidymodels. It’s an attempt to redefine how you use R as a stats machine (the language’s original purpose).
The idea behind tidymodels, if I understand correctly, is to separate model specification from parameter estimation.
Instead of the base R approach to linear regression:
1
lm(formula = price ~ carat, data = diamonds)
you get something like:
1
2
3
linear_reg() %>%
set_engine("lm") %>%
fit(formula = price ~ carat, data = diamonds)
which is pretty weird if you’ve used R for any amount of time.
But once the weirdness wears off, you can see the appeal.
The function linear_reg() says “I have a linear model”, and set_engine("lm") says “estimate the parameters of that model with linear regression”.
By defining a model separately from the way you estimate the model’s parameters, you easily swap out one “engine” for another.
For instance, you can turn the frequentest model into a Bayesian model with minor edits:
1
2
3
linear_reg() %>%
set_engine("stan", prior = some_prior_distribution) %>%
fit(formula = price ~ carat, data = diamonds)
Is changing how people fundamentally do stats in a language too big an ask? Harvard University’s IQSS made a similar attempt some years ago to redefine modeling in R with it’s package Zelig, and I don’t think it caught on.
But it’s a different story with RStudio and tidyverse, for the simple reason that the tidyverse has way more market power than Harvard. My guess is that “tidy modeling” will catch on soon enough.
Is R getting more complex?
The tidyverse makes R easier to use, but it’s not a free lunch.
A major downside about the tidyverse is that it is still very much in development and slightly unstable, and the authors acknowledge this.
Others worry the tidyverse will effectively become its own language, segment the market of R users, and ultimately reduce innovation (because different segments can’t “talk” to each other).
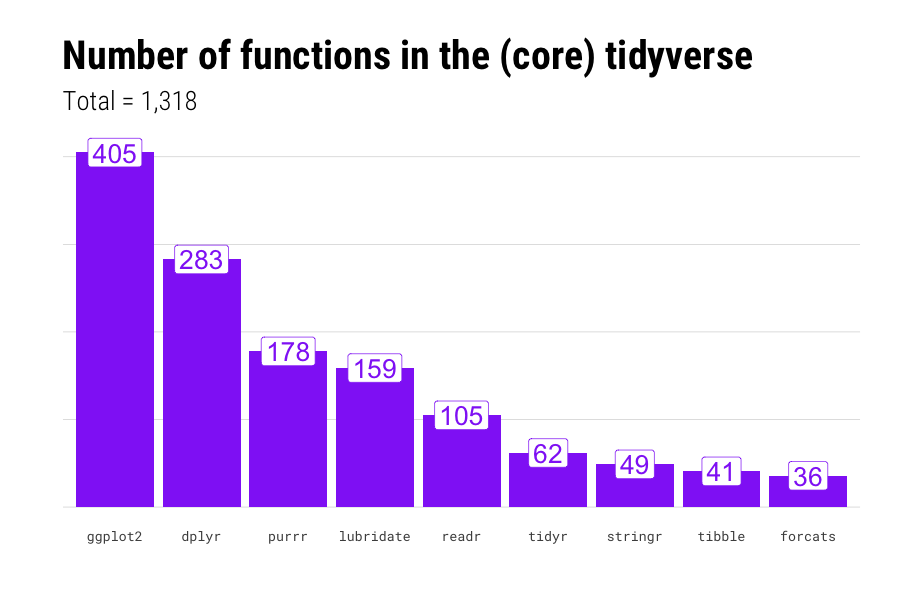
Still another concern is that the tidyverse is too complex. Base R has about 2,000 functions. There are over 1,000 functions in the “core” tidyverse alone (though you can get by with just a handful, especially when teaching):
But to me the bigger picture is that R as a whole is becoming more complex.
Not only are more and more packages released every year (tidy or not, developers were productive in lockdown!):
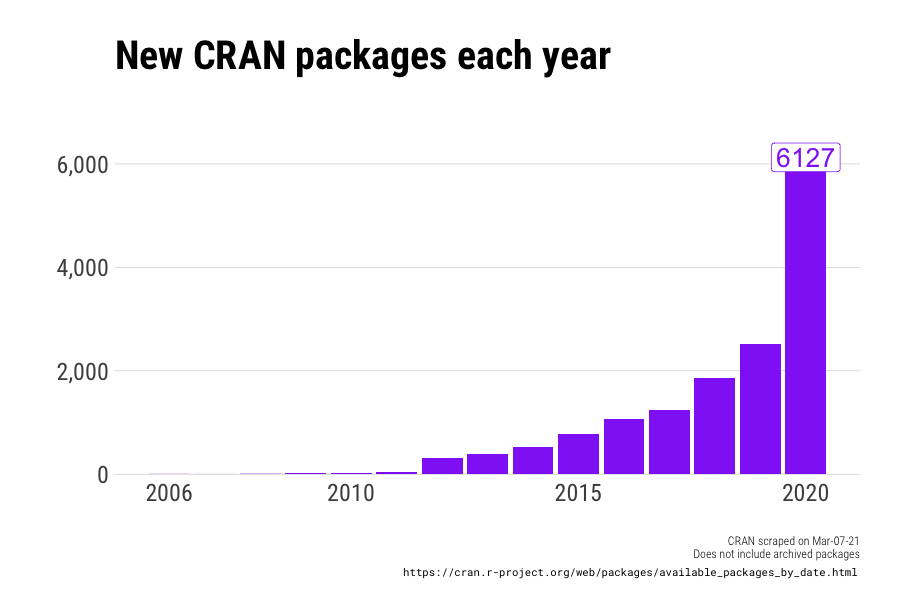
but they are becoming more complex, in that newer packages are increasingly dependent on other packages (exposing them to bugs and failures down the road):
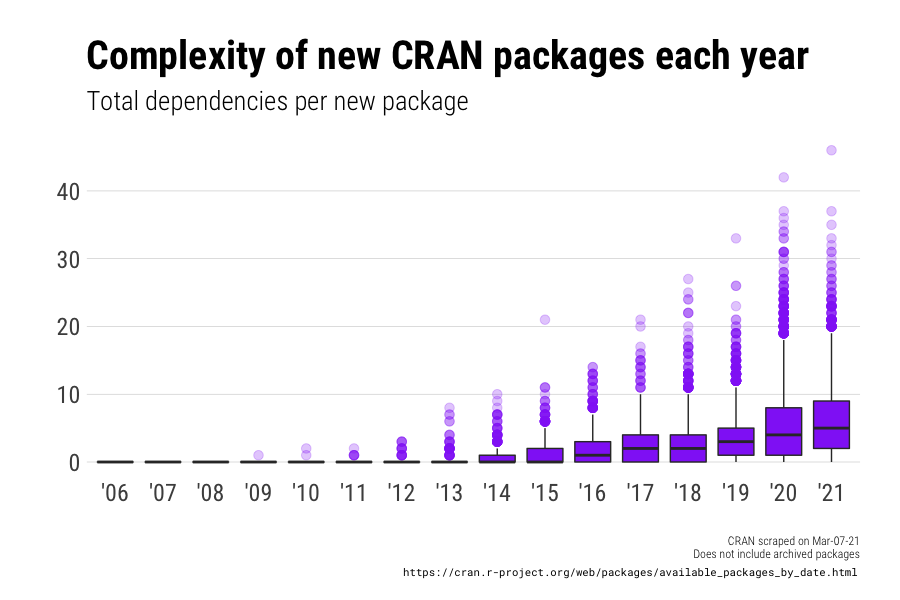
In the last decade there has been a 2000% increase in the maximum number of imports per package. The maximum dependencies in any package in 2010 was two. So far in 2021 there is already a package with 46 dependencies.
Many new packages will probably fade away, just like how most new scientific discoveries are forgotten. Allowing users to evolve the language organically instead of some central authority increases innovation. But when does innovation become chaos? At what point do developers say, screw it, let’s write a new language?
Politics and the R Language
At the end of the day, it’s not the language that matters, it’s what people do with it.
The tidyverse changes how we code. Does how we code shape how we solve problems and make discoveries?
It’s similar to Orwell’s observation that how we talk and write influences how we think. Just imagine if Old George programmed.
Code
The code to scrape CRAN and make these plots is on GitHub.
-
Why write “I am bullish on this stock and will hold it through thick and thin” when you can just write “💎🤲”. ↩
-
Or maybe this just means tidyverse users are worse coders! I doubt it. ↩
-
Check out this debate on Hacker News. ↩
-
If you’re wondering how many times I’ve used the word “tidyverse” so far, I’ve lost track. ↩
-
ggplot2 was released a year before Stack Overflow was founded in 2008, which probably stunted its early growth. Right now it’s tidyverse package with the most questions. ↩